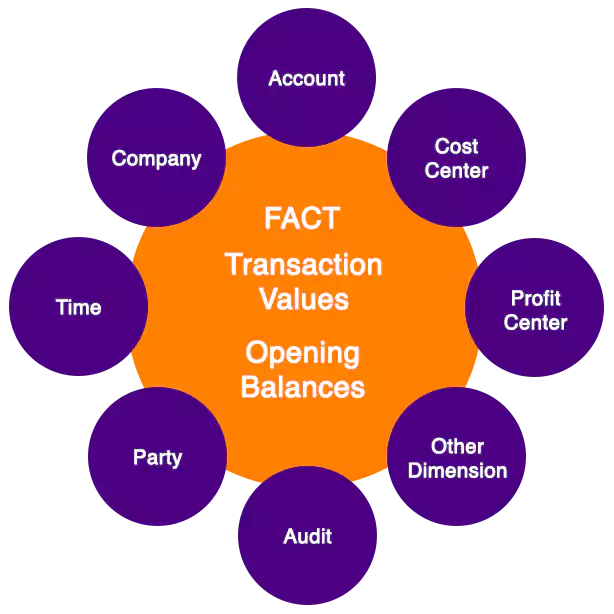
How to model a Semi-Additive fact? It is a common problem faced during Data Warehouse design phase. Prime example to discuss this scenario is Finance data model that stores General Ledger fact data. GL data is additive in nature across all dimensions, but only with reference to time context i.e. dimension. Primary reason for this behavior is the definition of “starting point”, which will be the date on which the opening balances were updated and normal transactions were henceforth entered in the system. Although opening balance is a fact, it has different contextual interpretation with respect to normal transactions. For any report requirement, this “starting point” must be considered into account for all subsequent calculations.
In reporting layer, it is a two step process to correctly derive a semi-additive fact. Firstly, the logic for calculating a beginning value based on time context is achieved by simply aggregating all values until the time reference provided. Subsequently, report logic references the starting value arrived in previous step to derive remaining measures in the report. Calculations such as starting value, measures etc., can be delegated to database, but the two step process is still required albeit in database layer.
Performance From run-time performance point of view, a full table scan is always required for reporting semi-additive measures. Due to this caveat, multiple aggregate tables are built at different levels of lower granularity based on analysis patterns.For example, the grain of fact table will be at each transaction level and aggregates can be built with lower grain at day and month level.

Data Model Modeling the fact table can be done by either keeping a single fact table wherein starting balances are embedded as part of the loading process. Alternatively, two fact tables with the same structure where one is loaded with opening balances and another is updated with transactions. These two tables can be aligned through union in a view or materialized view for analysis. The second option only enables to logically manage the data.
SAP BW is a tightly coupled with SAP ERP system. It has Data Model provision to embed the aggregation type within a Key Figure and identify the time context with granularity in the Cube/ADSO. Data loading process also is split into opening balances versus transaction data. During reporting, the actual calculation is performed by OLAP engine i.e not database delegated.
SAP HANA provides pre-defined views that follow logic described in this article, which is again calculated dynamically by Calc Engine and not database delegated.