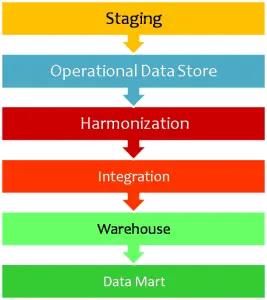
During the modeling exercise of a data warehouse, the decision regarding dimension and fact table design is implemented at the ‘Data Mart’ layer. This is the final layer, wherein all the data is ready for reporting after tasks such as data cleaning, data consolidation, business logic application, etc., are completed. Fact table types predominantly fall under two categories. Classifying a fact table into these categories is dependent on the behavior of underlying fact data i.e., Measure/Metric/KPI. In order to understand different types of fact data, refer to the post ‘Types of Fact Data – KPI Perspective. ‘
Two types of fact tables are ‘Transaction’ and ‘Snapshot’, which are unique in their own aspects and have different data loading strategies.
Transaction:
Fact data tables of this type hold the source record as-is without any modifications to actual data. Exceptions to this rule are the standard business rules that are applied to enhance the data. This is the most prevalent type of fact table and source facts are cumulative in nature. A good example of this scenario is Sales Order Facts and Purchase Order Facts.
Snapshot:
A snapshot table has non-cumulative facts and hence the design includes a ‘Time’ context, which is mandatory. Inventory data and Financial General Ledger data are examples of this type of fact. The underlying data is calculated along the defined Time context and populated in the fact table.
Fact table types also impact data loading strategy. From an ETL perspective, Transaction facts can be loaded with delta data. Snapshot tables, on the other hand, are always fully truncated and loaded.
Accumulating Snapshot is another commonly used term, which is more of a hybrid between the previous two types. In several large-scale DW/BI projects, apart from the two broad fact table types, based on requirement and performance perspective, such hybrid solutions are implemented.
Often missed-out types are aggregate tables that exist solely for performance reasons. These are slices of the main fact table data that are at a higher granularity and find heavy usage in analysis types of scenarios.
SAP BW: One can define multiple aggregates on a Cube that are data slices of the main cube and the server automatically decides to fetch data from either Aggregate view or main Cube based on actual query that is executed.
SAP BOBJ: A special function called @aggregate_aware, when defined in the meta data layer i.e. universe, provides cue to the server to fetch data from aggregate tables instead of main fact data.