The Data Warehouse/Business Intelligence system frequently needs to capture or derive historical changes when the source only provides the latest data snapshot.
Typically, generating history is viewed from the Slowly Changing Dimension (SCD) perspective. Logically, it is correct because fact data is immutable by nature as it refers to an event in the transaction system. ETL tools today have predefined transformations that can identify a change in the data and flag (e.g., Table Comparison & History Preserve in BODS) them accordingly. Using the flag (i.e., Insert, Update, or Delete) in the previous step, the ETL pipeline processes the data further based on business logic.
Key Attributes and Tracking Attributes
When we look deeper, these ETL transformations depend on two factors to perform the check and update. Among the two factors, ‘key attribute(s)’ forms the premise for capturing history, and the ‘tracking attribute(s)’ will be referenced during the check and update process.
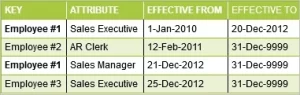
Use Case – CRM Opportunity Analysis
CRM Opportunity analysis provides a good use case for users to analyze the history of changes and associated activities. For simplicity, the example here shows a single key attribute and one tracking attribute, which along with date attributes show various changes to the data over time. In real-world scenarios, the key can be a composite key and tracking attributes can be more than one.
Scenario with Multiple Key Attributes
In a generic sense, consider a scenario wherein multiple key attributes are to be used to track change. In the CRM context, Order Value, Account Owner, Status, Activity, Contact Person, Close Date, etc. can change multiple times, which impacts the number of fields defined as ‘key attributes’. Standard ETL transformations can handle such scenarios, but there are a few tricks that can be employed to improve performance. ETL tools execute multiple select queries against the database with target table data in order to perform the comparison against new snapshot data. This might lead to inefficiency for large volumes of data.
The focus here is scenarios where the latest snapshot is provided by the source system. Without using ETL transformations, if we are to derive the flags (i.e., I, U, D), it is complicated without long procedures to scan all table content. The classic workaround is to create a single field that is concatenated value of all key attribute fields and use the same as the key attribute. This “key attribute” can be a large character field that is easier to manage and create indexes upon for performance, which need not be exposed to reporting layer.
MD5 Hash as Key Attribute
Adding to that idea, a cool and nifty feature is the MD5 hash that can be generated on the ‘key attribute’. It is a standard function available in all databases (e.g., HASHBYTES (‘MD5′,’ text value here’) in MS SQL Server) which has roots in cryptography. An MD5 hash has a constant length and always stays the same for a string of any length. Keeping this field as a ‘key attribute’ is more efficient for processing lookups and managing indices. Sample text and MD5 hashes are below.
- Hash: 3f4190b90136c5ed60a56a558ff6bbf1
- String: CUST001~JOHN~USA~MBA~12YEXP~20PROJ~AINC~Senior Consultant~100K
- Hash: caa08e04e6c31b7483d5a0278dfb245a
- String: CUST001~JOHN~USA~MBA
In this approach, we are effectively keeping the ETL configuration simple by creating the ‘key attribute’ column in delegated manner, which will aid in performance and management.
NOTE: SAP HANA HASH_MD5 function processes the MD5 in binary mode than character mode and type conversions are required before converting the data.