Data Lakes were envisioned as the next generation of data warehouse where structured reporting and ad-hoc data streams can be curated into a single data store. The sad reality today is that many data lake initiatives failed to deliver desired results with the data lake turning into a a hodgepodge collection of multiple data sets and hence the term “data swamp”. This phenomenon was noticed early during the hype cycle and highlighted by Gartner in a series of articles addressing this issue.
Goal of a data lake was simple and envisaged to bridge the functionality gaps faced by analysts, business users and data scientists alike. Data lakes were envisioned as a single point of entry with full access control security and curated data to fulfill organizational wide needs. Two aspects of this architecture stood apart
- Support structured and un-structured data – Key benefit and seen as moving away from shackles of the constraints posed by traditional data warehouses
- Data Ingestion – Push methodology thereby decoupling source systems to staging layer and enable fully automated data integration pipelines as well as ad-hoc self service option to upload data
A Data lake environment was not restricted to one system that addresses all functionalities required. Typically, a simple data lake setup will have a Relational, NoSQL and BLOB storage types accompanied by a data ingestion layer to push data and analytics layer for processing.
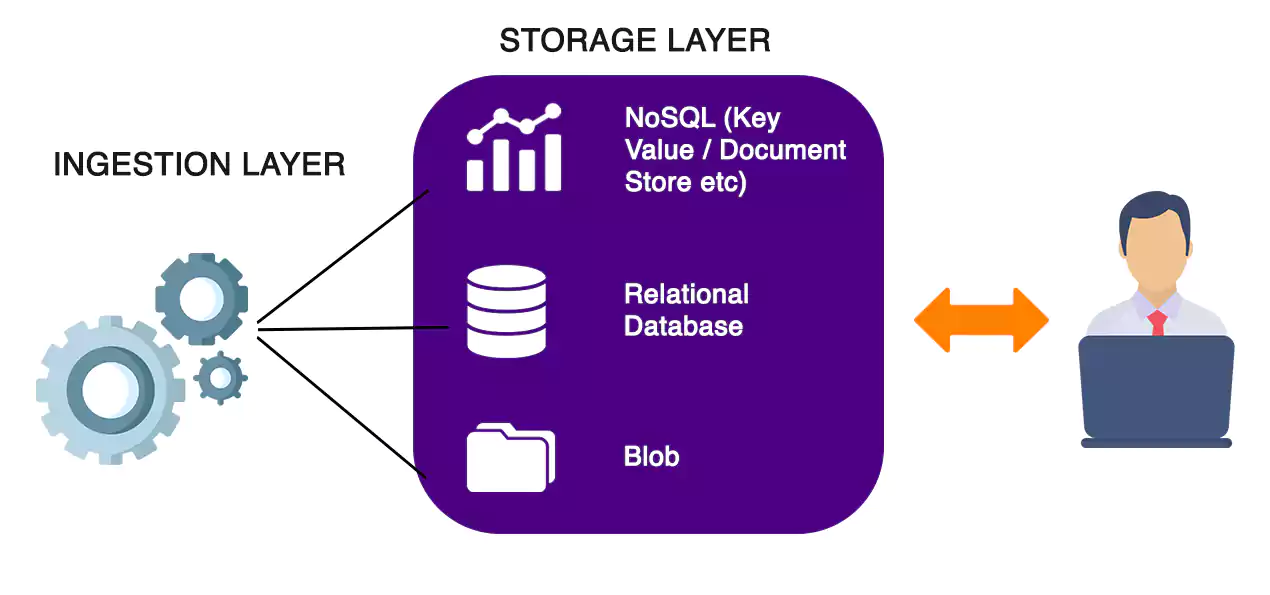
The issue of data lake becoming a data swamp arise’s when the data model changes over time from reporting perspective. Data swamping” issue slowly seeps into the system leading to partially correct data sets thereby users lack trust in the final data set. Both entry points to the data lake i.e. Data Ingestion pipeline and user self service changes creep over time. Unlike traditional data warehouse environments, where any change is meticulously captured beforehand and propagated across layers, a data lake cannot implement such a mechanism.
One popular option emphasized in many requirements as well as offerings from many NoSQL vendors is the option to enforce a schema during write and read. Essentially the schema enforcement enables a NoSQL database to function similar to Relational database by forcing the data to be formatted, data type corrected and matched with fields before saving the data set.
Schema enforcement goes against the principles of NoSQL databases wherein “schema on read” was only supported. In order to keep the legacy alive NoSQL vendors are providing partial schema enforcement where some parts of the data lake can have schema enforced whereas others can behave like traditional NoSQL database. (E.g. MongoDB provides the functionality at collection level, where two collections can co-exist with one collection having strict schema enforcement)
Schema enforcement for NoSQL is here to stay and it is a must have feature for all Data Architects designing at-scale analytical systems and removes many redundant features from Data Ingestion pipeline.