A simple, yet powerful concept used during data analysis that categorizes the data into different buckets/bins. One important point to remember is that ‘binning’ and ‘clustering’ is not the same and vary considerably in logic and implementation.
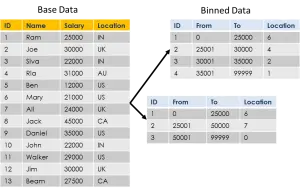
Binning is a quick and dirty way to start analysis on the data set. It is applied only to numeric data types and can be implemented on either dimension or fact data. Classifying customers based on age or income bracket is an example of binning on dimension and analyzing sales order values based on different quantity or value ranges is an example of binning on fact data.
A binning operation result always is the count of records in each data bucket defined, which helps in analyzing the distribution of a numeric data set. Based on the distribution we can decide on the types of ranges that can constitute different buckets/bins. One can define bins equally based on percentile values in a distribution or define ranges arbitrarily.
Binning is always a database delegated operation because of its inherent usage and application. Consider a scenario where the customer salary range is binned similar to the example above. Here, one must ensure that different customers are allocated different bins first before results are aggregated at reporting layer. The concept of delegating to the database applies to both Dimension and Fact data-based binning.
Binning ranges can be defined beforehand and used in analysis or computed at run-time. Tools in the market today provide the option to perform on-the-fly binning of data. Such analysis is done extensively by Sales & Marketing department to understand customer(s) and use their understanding in the Segmentation, Targeting & Positioning of a product.