“Late Arrival of Master Data” is a common problem encountered in large scale Data Warehouse Environments (DWE), especially where dependency of data spans multiple systems. In this scenario, facts arrive ahead of time and find out that required master data is not available in the dimension table. If this is not addressed, reports will not reconcile with the source system and users will not get correct picture on the correct status.
As a standard practice, while scheduling ETL data load jobs, the dimension load i.e. master data is loaded first. Transactional data i.e. facts are loaded second in the sequence. This process ensures that fact data is updated with proper master data assignment.
There is no shortcut here, but only different methods of handling and processing data records.
Hold and Release
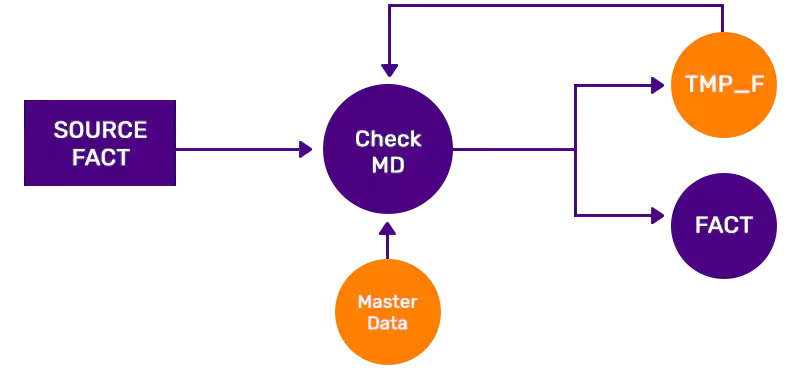
This is the easiest and simplest approach to implement. The ETL job workflow is designed with two distinct parts. First part of the ETL logic checks whether master data is available for each fact record. If an error is detected i.e. master data is not found, the erroneous fact record is loaded into a temporary fact table or holding Second part of the ETL job starts after fact data is processed. Data in temporary fact table is again checked against master data and fact records that now have valid master data are loaded into main fact table and erroneous ones are retained in holding table. Main disadvantage of this approach is that the temporary fact data may be held in temporary area without visibility to user for indefinite period of time resulting in logic fallacy in reporting.
Unassigned/Dummy Master Record
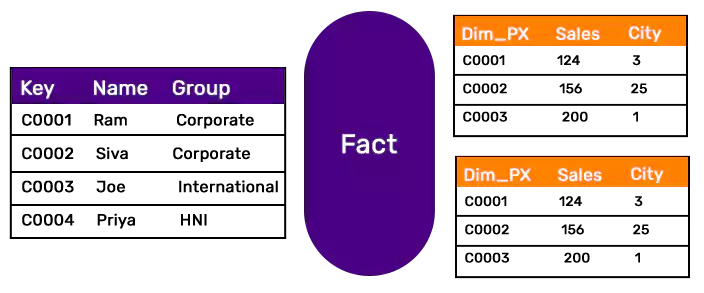
A slight variation from the previous method wherein the isolation of invalid records is addressed. In this concept, ETL workflow links the fact without master data with a dummy master record.
From reporting perspective data is immediately available after the loading process is complete. This is again a temporary solution and on daily basis, another ETL job has to check the facts that are marked as dummy and re-assign them to correct master data record as and when it becomes available and correct the entry in fact table.
Generate Master Record with Key
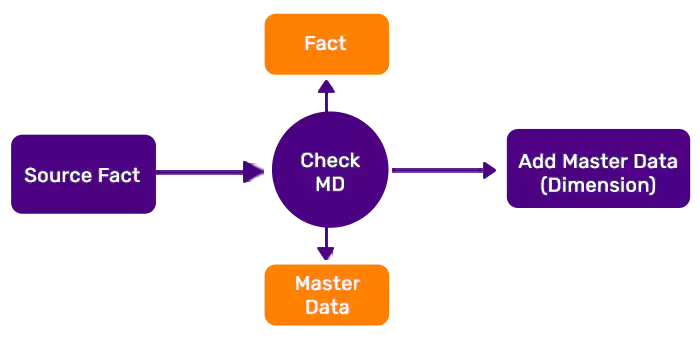
This approach is widely adopted in majority of data warehouse designs. As and when a fact record is encountered without values in dimension table, the ETL job branches out to load and update the master data first. In this scenario, a new master data record is inserted in dimension table only with the “Key” value. All other attributes are left untouched because the ETL workflows for master data will update them as and when data becomes available. If surrogate key needs to be generated as part of design, the primary key and surrogate key are updated accordingly.
Points to be noted
- All approaches above will work only when source fact data comes with a primary key column
- Look back and update logic will work only when detailed data is available in either Staging or Integration layers
- In case of slowly changing dimensions (SCD), the approaches mentioned above will not be a direct fit. The ETL workflow is slightly complicated depending on type of SCD (i.e. 2 or 3) is managed for the dimension in question.
- If surrogate keys are used Dimension data load workflow and fact data load workflow must be synchronized. If not, there are chances of multiple surrogate keys generated for a single key field.
- Care should be taken so that data is not updated in the fact table without fulfilling referential integrity constraints.
NOTE: SAP BW handles by generating a surrogate key (SID) so that in future the same primary key comes from source system, it is just updated internally. Data will be available for reports as “Unassigned” until then.