Term “Range Dimension” does not imply a new type of dimension model, instead it refers to a common scenario encountered in BI projects. It is a combination of Data Modeling and ETL technique to fulfill needs of end users. This is slightly different from Ageing and Binning, which is explored in a different article.
Need for a Range Dimension arises when an dimension attribute is a continuous variable i.e. numeric in nature with a wide range of values. Here is a quick look at Customer Dimension as an example and here are some attributes that are discrete versus continuous in nature,
| Discrete | CONTINUOUS |
|---|---|
|
|
When analysis has to be performed based on “Income Level” of a customer, the data will be distributed over wide range of values. Range_Dimension_1Example to the right shoes from an user experience perspective of the need for such dimensions. Defining and applying ranges are heavily used by Sales and Marketing teams to classify and identify different segments.
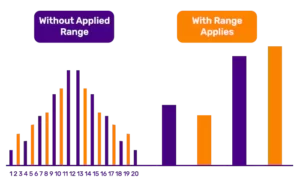
A range dimension can be static or dynamic based on the architecture. Most flexible data model uses the range dimension in a snowflake pattern and as a lookup table in the ETL job which loads main dimension data to populate values. This gives business user an option to change the range assignments as and when needed. Advantage of populating the ranges(s) beforehand gives an edge from performance perspective because data is classified and stored in the database.

In cases where a dedicated range dimension cannot be used, binning comes in handy to apply the same logic. This approach relies heavily on the reporting tool and majority of tools in market today have options to implement such logic. One major drawback here occurs when large data sets are encountered because the processing logic has to be executed during run time and every time at the reporting layer.